作者: 🐤小鸡 & 韩宇栋
日期: 2026-02-07
关键词: LLM, Post-training, SFT, DPO, GRPO, Unsloth, TRL
1. 什么是后训练?
大模型从诞生到可用,经历两个阶段:
| 阶段 | 目标 | 数据 |
|---|
| 预训练 (Pre-training) | 学习语言知识,预测下一个 token | 万亿级无标注文本 |
| 后训练 (Post-training) | 学会遵循指令、对齐人类偏好 | 千级~万级标注数据 |
后训练把一个"什么都知道但不会说话"的 base model,变成一个"能听懂你说什么、按要求回答"的 instruct model。
2. 三种技术路线总览
| SFT (监督微调) | DPO (直接偏好优化) | RL / GRPO (强化学习) |
|---|
| 核心思想 | 照着标准答案学 | 对比好坏答案,学会选择 | 自己生成答案,由奖励函数打分 |
| 一句话 | 照着抄 | 学会挑 | 自己悟 |
| 数据格式 | (prompt, response) | (prompt, chosen, rejected) | prompt + reward function |
| 标注成本 | 中等 | 高 | 低(但 reward 设计难) |
| 训练稳定性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 效果上限 | 受限于数据 | 精细打磨 | 最高(能超越数据) |
| 提升模型能力? | ❌ 不提升,只激活 | ❌ 不提升,只筛选 | ✅ 真正提升 |
| 显存占用 | 1x | 2x (需 ref model) | 2-3x (在线生成) |
| 典型用例 | 指令遵循、角色扮演、领域 QA | 安全对齐、风格调优 | 数学推理、代码生成 |
关键认知:后训练 ≠ 都能让模型变聪明
这是一个常见误区。三种方法对模型能力的影响本质上不同:
SFT — 激活已有能力,不创造新能力
模型在预训练阶段已经从万亿 token 中学到了知识。SFT 只是教它用正确的格式表达出来。类比:你已经会做菜了,SFT 只是教你按菜谱格式把做法写出来。如果 base model 不懂量子力学,SFT 再怎么训也教不会。
DPO — 在已有能力间选择,不创造新能力
DPO 在模型已有的多种回答倾向中,强化好的、压制差的。类比:你会做 10 道菜,有些好吃有些难吃,DPO 让你以后只做好吃的那几道。它没有教你新菜,只是帮你"选择性遗忘"坏习惯。
GRPO/RL — 真正提升能力,能超越训练数据
这是唯一能让模型"变聪明"的方法。通过试错探索,模型能发现训练数据中不存在的新策略。DeepSeek-R1 的例子最典型:通过 GRPO 训练,模型自己"顿悟"了 chain-of-thought 推理,学会了把复杂问题拆解成步骤——这是训练数据里没有明确教的行为。但前提是必须有可验证的 reward(比如数学答案对不对),否则模型不知道往哪个方向探索。
因此,标准训练顺序的逻辑是:
- SFT 激活表达能力 → 2. DPO 打磨输出偏好 → 3. RL 突破能力上限
其中只有第 3 步真正在"变聪明",前两步更像是"让模型说得更好"而非"让模型想得更好"。
3. SFT — 监督微调
3.1 原理
SFT 是最直觉的后训练方式。给模型看大量 (input, ideal_output) 对,用标准交叉熵损失训练模型最大化 $P(\text{output} | \text{input})$。
类比:老师给你看范文,你学着写。写得越像范文,分数越高。
3.2 数据格式
1
2
3
4
5
| {
"instruction": "把下面的句子翻译成英文",
"input": "今天天气真好",
"output": "The weather is really nice today."
}
|
常见数据格式:
- Alpaca 格式:
instruction + input + output - ShareGPT 格式:多轮对话
conversations: [{from: "human", value: "..."}, {from: "gpt", value: "..."}] - Chatml 格式:
<|im_start|>user\n...<|im_end|>\n<|im_start|>assistant\n...<|im_end|>
3.3 数据质量原则
- 输出质量 = 模型上限。数据里写的多好,模型最多学到那么好
- 多样性 > 数量。1000 条覆盖 100 种任务 > 10000 条只覆盖 5 种任务
- 格式一致。统一使用同一种 prompt template
- 去重。重复数据会导致过拟合
3.4 Unsloth + TRL 实战
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| from unsloth import FastLanguageModel
from trl import SFTTrainer, SFTConfig
from datasets import load_dataset
# ① 加载模型(4bit 量化,省显存)
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/Qwen2.5-7B",
max_seq_length=2048,
load_in_4bit=True, # QLoRA: 4bit 量化
dtype=None, # 自动检测
)
# ② 添加 LoRA adapter
model = FastLanguageModel.get_peft_model(
model,
r=16, # LoRA 秩,越大容量越大
lora_alpha=16, # 缩放因子
lora_dropout=0, # Unsloth 优化下设 0 即可
target_modules=["q_proj", "k_proj", "v_proj",
"o_proj", "gate_proj", "up_proj", "down_proj"],
)
# ③ 准备数据
dataset = load_dataset("json", data_files="sft_data.jsonl")
def format_prompt(example):
return f"""<|im_start|>user
{example['instruction']}
{example['input']}<|im_end|>
<|im_start|>assistant
{example['output']}<|im_end|>"""
# ④ 训练
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset["train"],
args=SFTConfig(
per_device_train_batch_size=4,
gradient_accumulation_steps=4, # 有效 batch = 4×4 = 16
num_train_epochs=3,
learning_rate=2e-4,
warmup_steps=10,
fp16=True, # 混合精度
logging_steps=10,
output_dir="./sft_output",
seed=42,
),
)
trainer.train()
# ⑤ 保存
model.save_pretrained("./sft_model")
tokenizer.save_pretrained("./sft_model")
# ⑥ 导出 GGUF(可选,供 Ollama/llama.cpp 使用)
model.save_pretrained_gguf("./sft_gguf", tokenizer,
quantization_method="q4_k_m")
|
3.5 适用场景
✅ 有高质量标注数据时的首选
✅ 快速原型验证
✅ 领域适配(法律、医疗、金融 QA)
✅ 格式控制(JSON 输出、特定模板)
✅ 角色扮演 / 人设定制
❌ 不适合:想让模型"变聪明"(SFT 只能教模式,不能教思考)
4. DPO — 直接偏好优化
4.1 原理
DPO 是 RLHF 的简化替代方案。传统 RLHF 需要训练一个 reward model 再做 PPO,流程复杂。DPO 直接用偏好数据训练,跳过 reward model。
损失函数核心思想:
- 拉大
chosen(好回答)的概率 - 压低
rejected(坏回答)的概率 - 同时用 reference model 做 KL 约束,防止模型跑偏太远
$$\mathcal{L}_{\text{DPO}} = -\log \sigma \left( \beta \left[ \log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)} \right] \right)$$其中 $y_w$ 是 chosen,$y_l$ 是 rejected,$\beta$ 控制约束强度。
类比:老师给你看两篇作文 A 和 B,告诉你"A 比 B 好"。你不需要知道 A 得了几分,只需要学会 A 的优点、避免 B 的缺点。
4.2 数据格式
1
2
3
4
5
| {
"prompt": "请用一句话解释什么是机器学习",
"chosen": "机器学习是让计算机从数据中自动学习规律并做出预测的技术。",
"rejected": "机器学习就是AI,就是人工智能,很厉害的技术。"
}
|
数据构造方法:
- 人工标注:给标注员看两个回答,选更好的
- 模型生成 + 人工筛选:用模型生成多个回答,人工挑好坏
- 强弱模型对比:GPT-4 的输出当 chosen,小模型输出当 rejected
- AI 反馈 (RLAIF):用另一个模型当裁判打分
4.3 Unsloth + TRL 实战
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| from unsloth import FastLanguageModel, PatchDPOTrainer
from trl import DPOTrainer, DPOConfig
# 重要:Unsloth 的 DPO 优化补丁
PatchDPOTrainer()
# ① 加载 SFT 后的模型(DPO 通常在 SFT 之后做)
model, tokenizer = FastLanguageModel.from_pretrained(
"./sft_model",
max_seq_length=2048,
load_in_4bit=True,
)
model = FastLanguageModel.get_peft_model(model, r=16)
# ② 准备偏好数据
dpo_dataset = load_dataset("json", data_files="dpo_data.jsonl")
# ③ 训练
trainer = DPOTrainer(
model=model,
# ref_model=None, # Unsloth 自动处理 reference model
tokenizer=tokenizer,
train_dataset=dpo_dataset["train"],
args=DPOConfig(
beta=0.1, # KL 约束强度。0.1~0.5,越小越激进
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
learning_rate=5e-5, # 比 SFT 小一个数量级
num_train_epochs=1, # DPO 通常 1-2 epochs 就够
warmup_ratio=0.1,
fp16=True,
logging_steps=10,
output_dir="./dpo_output",
),
)
trainer.train()
model.save_pretrained("./dpo_model")
|
4.4 关键参数
| 参数 | 推荐值 | 说明 |
|---|
beta | 0.1 ~ 0.5 | 越小越激进地偏向 chosen,越大越保守 |
learning_rate | 1e-5 ~ 5e-5 | 比 SFT 小,避免灾难性遗忘 |
num_train_epochs | 1 ~ 2 | 过多会过拟合 |
max_length | 1024 ~ 2048 | chosen + rejected 都要 tokenize |
4.5 适用场景
✅ 安全对齐(减少有毒/有害输出)
✅ 风格/语气调整(更专业、更友好、更简洁)
✅ 减少幻觉(好回答=有据可查,坏回答=瞎编的)
✅ 品牌调性定制
❌ 不适合:教模型新知识(DPO 只能在已有能力间选择,不能创造新能力)
5. RL / GRPO — 强化学习
5.1 原理
RL 是后训练的"终极武器"。模型自己生成回答,由 reward function 打分,通过策略梯度不断优化。
GRPO (Group Relative Policy Optimization) 是 DeepSeek 提出的简化版 PPO:
- 对每个 prompt 采样一组(group)回答
- 用组内相对排名作为 advantage(而非训练单独的 value model)
- 省掉了 critic model,训练更简单
PPO vs GRPO:
| PPO | GRPO |
|---|
| 需要 critic/value model | ✅ | ❌ |
| 显存占用 | 更高 | 更低 |
| 实现复杂度 | 高 | 中 |
| 效果 | 经典可靠 | 同等甚至更好 |
5.2 奖励函数设计
奖励函数是 RL 的灵魂。常见类型:
① 基于规则的可验证奖励(推荐,最可靠)
1
2
3
4
5
| def math_reward(completion, prompt):
"""数学题:答案对了 +1,错了 -1"""
predicted = extract_answer(completion)
ground_truth = get_correct_answer(prompt)
return 1.0 if predicted == ground_truth else -1.0
|
② 基于格式的奖励
1
2
3
4
5
6
7
8
| def format_reward(completion, prompt):
"""检查输出是否符合指定格式"""
score = 0.0
if "<think>" in completion and "</think>" in completion:
score += 0.5 # 有思考过程
if extract_final_answer(completion) is not None:
score += 0.5 # 有最终答案
return score
|
③ 基于模型的奖励(reward model 打分)
1
2
3
4
| def model_reward(completion, prompt):
"""用另一个模型打分"""
score = reward_model.predict(prompt, completion)
return score
|
5.3 Unsloth + TRL 实战 (GRPO)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| from unsloth import FastLanguageModel
from trl import GRPOTrainer, GRPOConfig
import re
# ① 加载模型
model, tokenizer = FastLanguageModel.from_pretrained(
"./sft_model", # 从 SFT 模型开始
max_seq_length=2048,
load_in_4bit=True,
)
model = FastLanguageModel.get_peft_model(model, r=16)
# ② 定义奖励函数
def correctness_reward(completions, prompts, **kwargs):
"""数学正确性奖励"""
rewards = []
for comp, prompt in zip(completions, prompts):
# 提取 <answer>xxx</answer> 中的答案
match = re.search(r'<answer>(.*?)</answer>', comp)
if match:
predicted = match.group(1).strip()
correct = kwargs.get("answer", [""])[0]
rewards.append(2.0 if predicted == correct else -1.0)
else:
rewards.append(-0.5) # 格式不对也扣分
return rewards
def format_reward(completions, **kwargs):
"""格式奖励:鼓励 <think>...</think><answer>...</answer> 结构"""
rewards = []
for comp in completions:
score = 0.0
if "<think>" in comp and "</think>" in comp:
score += 0.5
if "<answer>" in comp and "</answer>" in comp:
score += 0.5
rewards.append(score)
return rewards
# ③ 准备 prompt 数据
# {"prompt": "计算 127 × 38 = ?", "answer": "4826"}
prompts_dataset = load_dataset("json", data_files="math_prompts.jsonl")
# ④ 训练
trainer = GRPOTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=prompts_dataset["train"],
reward_funcs=[correctness_reward, format_reward],
args=GRPOConfig(
num_generations=4, # 每个 prompt 采样 4 个回答
max_completion_length=512, # 最大生成长度
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
learning_rate=1e-5, # RL 用更小的学习率
num_train_epochs=1,
logging_steps=5,
output_dir="./grpo_output",
),
)
trainer.train()
model.save_pretrained("./grpo_model")
|
5.4 关键参数
| 参数 | 推荐值 | 说明 |
|---|
num_generations | 4 ~ 8 | 每 prompt 采样数,越多 advantage 估计越准 |
learning_rate | 5e-6 ~ 2e-5 | 比 DPO 更小 |
max_completion_length | 256 ~ 1024 | 控制生成长度 |
temperature | 0.7 ~ 1.0 | 采样温度,太低缺多样性 |
5.5 适用场景
✅ 数学推理(DeepSeek-R1 的核心方法)
✅ 代码生成(单元测试通过 = reward)
✅ 结构化输出(JSON/XML 格式合规性)
✅ 任何有可验证评判标准的任务
❌ 不适合:开放式创意任务(难设计 reward)
❌ 不适合:没有 SFT 基础的 base model(模型不会生成有意义的回答)
6. 训练流水线与最佳实践
6.1 标准训练流水线
1
2
3
4
| ┌─────────────┐ ┌─────────────┐ ┌──────────────┐
│ Base Model │────▶│ SFT │────▶│ DPO / GRPO │
│ (预训练) │ │ (学会说话) │ │ (说得更好) │
└─────────────┘ └─────────────┘ └──────────────┘
|
不要跳过 SFT! Base model 不懂指令格式,直接做 DPO/RL 效果极差。
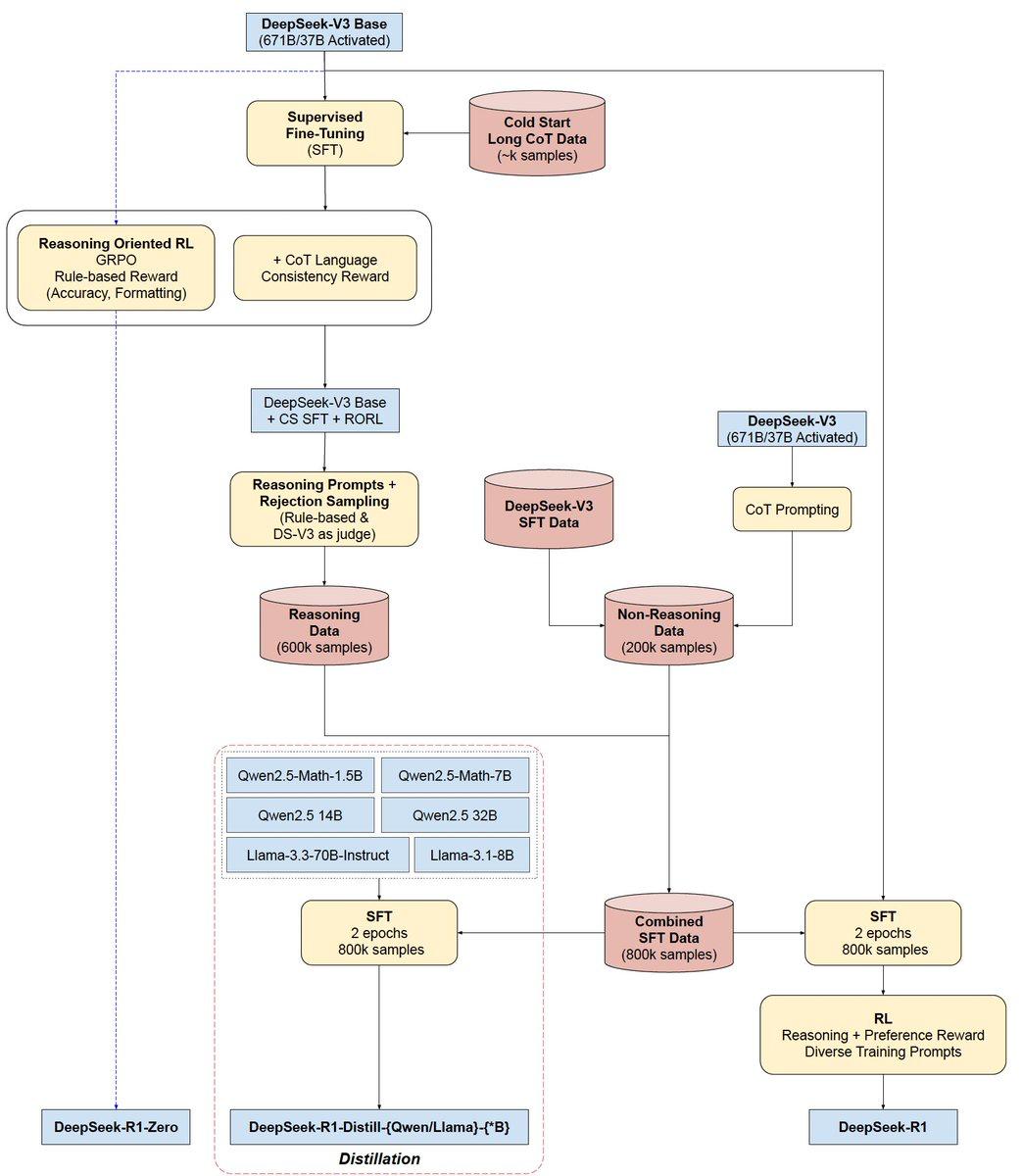
下图展示了 DeepSeek-R1 的完整训练流水线,清晰体现了 SFT → RL → 数据蒸馏的多阶段过程:
6.2 如何选择技术路线?
1
2
3
4
5
6
7
8
9
10
| 你有什么数据?
│
├─ 有 (input, output) 对 ──────────▶ SFT
│
├─ 有 (好回答, 坏回答) 对比 ───────▶ SFT → DPO
│
├─ 有可验证的奖励信号 ─────────────▶ SFT → GRPO
│ (数学答案、代码测试、格式检查)
│
└─ 三者都有 ───────────────────────▶ SFT → DPO → GRPO
|
6.3 硬件需求参考
| 模型大小 | SFT (QLoRA) | DPO (QLoRA) | GRPO (QLoRA) |
|---|
| 1.5B | 8 GB | 12 GB | 16 GB |
| 7B | 16 GB | 24 GB | 32 GB |
| 14B | 24 GB | 40 GB | 48 GB |
| 70B | 80 GB (A100) | 2×80 GB | 4×80 GB |
消费级显卡推荐:
- RTX 4090 (24GB):跑 7B QLoRA SFT/DPO 绰绰有余
- RTX 3090 (24GB):同上,速度略慢
- RTX 4060 Ti (16GB):7B QLoRA SFT 可以,DPO 勉强
6.4 常见坑
| 坑 | 原因 | 解决 |
|---|
| SFT 后模型变笨了 | 数据质量差 / 过拟合 | 提高数据质量,减少 epochs |
| DPO 效果不明显 | chosen 和 rejected 差异太小 | 增大对比差异 |
| GRPO 训练不收敛 | reward 设计不当 / lr 太大 | 简化 reward,降低 lr |
| 显存 OOM | batch size 太大 | 减 batch size,加 gradient accumulation |
| 灾难性遗忘 | lr 太大 / epochs 太多 | 减小 lr,用 LoRA 而非全量微调 |
7. 工具链总结
7.1 为什么选 Unsloth + TRL?
| 框架 | 优势 | 劣势 |
|---|
| Unsloth | 速度快 2-5x,显存省 70%,单卡友好 | 主要优化单卡场景 |
| TRL (HuggingFace) | 官方维护,SFT/DPO/PPO/GRPO 全覆盖 | 单独用较慢 |
| Unsloth + TRL | 两者优势结合:速度 + 功能 | — |
其他选择:
- LLaMA-Factory:Web UI 点点就能训,适合不想写代码的人
- OpenRLHF:分布式 RL,生产级部署
- Axolotl:配置驱动,社区活跃
7.2 从数据到部署的完整流程
1
2
3
4
5
6
7
8
9
10
11
| 1. 准备数据 (JSONL)
↓
2. 选基座模型 (Qwen2.5 / Llama3 / Gemma)
↓
3. SFT 训练 (Unsloth + TRL)
↓
4. [可选] DPO / GRPO 对齐
↓
5. 导出 (GGUF / safetensors)
↓
6. 部署 (Ollama / vLLM / TGI)
|
7.3 推荐学习资源
本文档基于 2026 年 2 月的框架版本编写,后训练领域发展迅速,建议关注各框架最新更新。